EN
April 2026

In this blog post we discuss what and how CorrelAid is self-hosting, why we decided to do so and what this has to do with cool kayaks.
DE
Dezember 2025

John Mark Shorack gibt in diesem Blogbeitrag einen Einblick in die Daten des „Wegweiser Kommune“ und zeigt, welche Möglichkeiten sie eröffnen. Im Rahmen des DatenDialogs 2025 in Gütersloh betreute John die entsprechende Datenherausforderung als Pate und arbeitete dabei mit den Daten des „Wegweiser Kommune“.
Juli 2025

Vom 4. bis 6. Juli 2025 haben wir in Konstanz das 10-jährige Jubiläum von CorrelAid gefeiert – gemeinsam mit fast 70 engagierten Menschen aus der Community. Die CorrelCon 2025 war mehr als nur eine Konferenz: Sie war ein Ort des Austauschs, der Inspiration und ein großes Dankeschön an alle, die CorrelAid in den letzten 10 Jahren mitgestaltet und zu dem gemacht haben, was es heute ist.
April 2025

Die sechste Ausgabe des DatenDialogs mit dem Open Data Forum, MobiData BW und einigen anderen konzentrierte sich vor allem auf zivilgesellschaftliche Initiativen. Nie zuvor waren so viele Datenherausforderungen aus diesem Bereich vertreten.
EN
März 2025

Despite my name tag's clear indication of my CorrelAid background, I felt somewhat like I was going undercover when I attended the German Data Science Days (GDSD) 2025. The GDSD, organized annually by the German Data Science Society, aims to foster collaboration between science, industry, and business. I currently do not work in either field, but I gained some interesting insights at the event that I believe may be of interest to civil society. The program and some of the talk materials can be accessed here.
Januar 2025

Neue Teammitglieder, neue Bildungsformate, neue Data4Good-Projekte, neue Datendinos!
2024 war wirklich ein aufregendes Jahr für CorrelAid. Durch den tatkräftigen Zuwachs in unseren haupt- und ehrenamtlichen Teams haben wir Bewährtes ausgebaut und viele neue Ideen aus, mit und für die Community realisieren können. Was genau im letzten Jahr passiert ist, und Datendinos damit zu tun haben, erzählen wir in unserem Jahresrückblick.
Oktober 2024

Mitte Oktober fand die CorrelCon 2024 statt – die jährliche Konferenz von CorrelAid und definitiv ein Jahres-Highlight! ✨
Oktober 2024

Wenn die Organisation wächst, kann das Durchführen und besonders auch das Auswerten von Teilnehmendenbefragungen zu einer Herausforderung werden. In einem Data4Good Projekt haben 5 CorrelAid-Volunteers für In safe hands e.V. einen automatisierten Auswertungsprozess und eine Webanwendung für ihre Wirkungsmessung entwickelt.
DE
Juni 2024

In diesem Beitrag blicke ich zurück auf meine Teilnahme am Kurs „R Lernen - Der Datenkurs von und für die Zivilgesellschaft“ - Spoiler: es hat sich wirklich gelohnt!
DE
Mai 2024

Im April haben wir wieder das Data Science Stipendium mit IOMIDS angeboten - Max war einer der Stipendiaten und berichtet im Interview von seiner Lernreise!
DE
April 2024

CorrelAid bietet in Zusammenarbeit mit IOMIDS das Data Science Stipendium an, um die Ausbildung in den Bereichen Data Science und künstliche Intelligenz für ehrenamtliche Zwecke zu fördern. Das Stipendium umfasst eine vollständige Übernahme der Kursgebühren für das Data Science Bootcamp von IOMIDS.
DE
März 2024
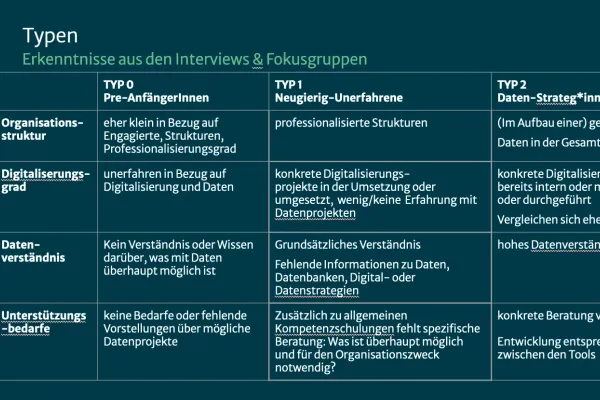
Anfang 2023 haben wir eine Bedarfsanalyse zum Thema Daten und Zivilgesellschaft durchgeführt. Die zentralen Erkenntnisse - Einteilung in drei Typen, Datenreifegradmodelle, Status Quo der Forschung - stellen wir in diesem Blog Post vor.
DE
Februar 2024

Der nun schon dritte Datendialog zwischen CorrelAid und der Bertelsmann Stiftung war ein voller Erfolg! Rund 40 Teilnehmer*innen aus unserem Data4Good Netzwerk nahmen trotz Schneechaos an dem 1,5-tägigen Event in München teil und brachten viele neue Impulse für insgesamt vier Projekte aus der Bertelsmann Stiftung ein.
Dezember 2023

Zum Jahresabschluss lassen wir die Ergebnisse unserer Arbeit, Veranstaltungen und Erlebnisse einmal Revue passieren. Viel Spaß beim Stöbern!
November 2023

Gefördert durch die Deutsche Stiftung für Engagement und Ehrenamt (DSEE) wird CorrelAid im Rahmen des transform_d Programms bis Ende 2024 einen neuen, einstiegsorientierten Datenkompetenzkurs konzeptionieren, erstellen und durchführen. Erfahre hier mehr zum Kurs und zum Beginn der Umsetzungsphase.
EN
Oktober 2023

It will soon be two years since CorrelAid has established the Ethics commission. In this blog post, we introduce you to the work of the Ethics commission and tell you more about what we have been doing during these last two years.
DE
August 2023

Das Konsortium des Civic Data Labs (CDL) startet in die praktische Umsetzung. Erfahre hier, was das CDL ist, was es konkret machen wird und wie CorrelAid daran mitwirkt.
DE
August 2023

Das Potential der Datenanalyse für die Zivilgesellschaft.
DE
August 2023

In unserem Newsletter für Februar 2016 erfahrt ihr alles über unsere strategischen Pläne, Core-Team Initiativen, derzeitige Projekte und vieles mehr.
DE
August 2023

Microsoft hatte einmal die Vision ‘A computer on every desk and in every home’. In diesem Sinne würde CorrelAids Vision lauten: "A data scientist in every non-profit-organisation."
DE
August 2023

Circa 30 engagierte Datenanalyst*innen aus ganz Deutschland kamen vom 25. Bis zum 27. 11.2016 im BonnLab zusammen, um sich über Data4Good auszutauschen, ihre technischen Skills zu erweitern und weiterzugeben und CorrelAid weiterzuentwickeln.
DE
August 2023

In dieser kurzen Bestandsaufnahme erfahrt ihr alles zu den Data4Good Projekten, die CorrelAid seit der Gründung vor 1,5 Jahren umgesetzt hat oder derzeit umsetzt.
DE
August 2023

Am Samstag, den 6. Mai, war CorrelAid zu Gast beim Data Viz BBQ des Data Viz Rhein Main Meetups.
DE
August 2023

Drei Highlights aus dem letzten Jahr und ein Blick nach vorn.
DE
August 2023

In Hamburg haben wir unser diesjähriges Netzwerk-Meeting gefeiert
DE
August 2023

Unser Datendialog dazu findet am 5. Oktober in Berlin statt
DE
August 2023

Ein Rückblick auf unsere Veranstaltung in München
DE
August 2023

Kick-off für unsere Data-for-Good-Lokalgruppen
DE
August 2023

Eindrücke von unserem jährlichen Get-together
EN
August 2023

An easy way to get news headlines from Newsapi.org
EN
August 2023
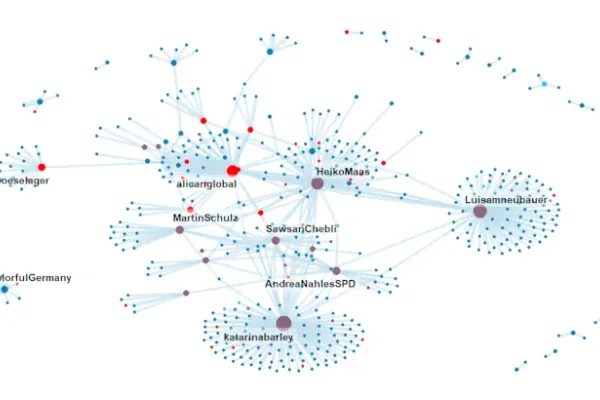
Analyzing the #We2 movement using Twitter data and R
August 2023

Ein Rückblick auf unseren Datendialog in Berlin unter dem Motto ‘European Data Lingo’
EN
August 2023

Magic happens when you put socially thinking data scientists together in a space for a weekend.
EN
August 2023

2020: A new chapter for Data for Good in Germany.
EN
August 2023

A Use Case for CorrelAid’s newsapi.org R Package
EN
August 2023
We think data scientists should be very intentional with what they do and don’t do right now. Here’s why.
EN
August 2023

In August we launched our first CorrelAidX challenge: Over the course of 8 weeks, we called on our local chapters to use regional data, provided by the state statistical offices, from their region and submit creative data projects using the python package developed by Datenguide in collaboration with CorrelAid. Have a look at the amazing outcomes!
DE
August 2023
Die Datenstrategie der Bundesregierung ist da. Nachdem wir uns bei CorrelAid seit 2015 mit allem beschäftigen, was mit Datennutzung in der Zivilgesellschaft zu tun hat, nehmen Frie (COO) und Johannes (Vorstandsvorsitzender) die Strategie einmal aus dieser Perspektive unter die Lupe.
EN
August 2023

As we are growing (and growing and growing), it is time to tackle old challenges with a shifted mindset: Both in our work with data analysts, scientists and enthusiasts and NPOs with a data-mindset, we want to become more effective and efficient, opening the doors to new fundraising and partnership opportunities.
EN
August 2023
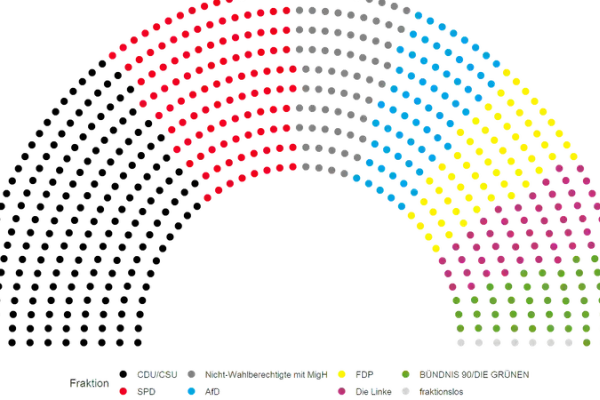
As part of a successful cooperation between Citizens For Europe, Arndt Leininger (long-time member of CorrelAid and assistant professor for political science research methods at Chemnitz University of Technology) and Julius Lagodny (PhD candidate in political science at Cornell University), CorrelAid volunteers met up for the first TidyTuesday inspired Challenge to explore different ways to visualize the potential electoral power of people with so-called migration background in Germany.
DE
August 2023

CorrelAid bietet in Zusammenarbeit mit IOMIDS das Data Science Stipendium an, um die Ausbildung in den Bereichen Data Science und künstliche Intelligenz für ehrenamtliche Zwecke zu fördern. Das Stipendium umfasst eine vollständige Übernahme der Kursgebühren für einen der Kurse von IOMIDS.
EN
August 2023

We’re looking for members for our new ethics commission! The commission will be reviewing CorrelAid activities to make sure that we live up to our aspiration to make the world better with data science. Run for the commision and help us do that!
DE
August 2023
CorrelAid bietet in Zusammenarbeit mit IOMIDS das Data Science Stipendium an, um die Ausbildung in den Bereichen Data Science und künstliche Intelligenz für ehrenamtliche Zwecke zu fördern. Das Stipendium umfasst eine vollständige Übernahme der Kursgebühren für einen der Kurse von IOMIDS.
DE
August 2023

Mit dem zwölfteiligen Kurs “R Lernen von und für die Zivilgesellschaft – Der Datenkurs für Anfänger*innen” wollen wir von CorrelAid e.V. die Menschen und Organisationen, die die Welt mit ihrer Arbeit besser machen wollen, dabei unterstützen, dies effektiver und effizienter zu tun.
August 2023

Heute, am Tag der Anerkennung von Freiwilligen, möchten wir bei CorrelAid uns bei allen unseren Freiwilligen bedanken, die unsere Mission unterstützen, Daten für eine bessere Welt zu nutzen. Ohne Eure Zeit und Euer Engagement wären wir nicht in der Lage, unsere Projekte und Initiativen umzusetzen - Danke!
DE
August 2023

CorrelAid bietet in Zusammenarbeit mit IOMIDS das Data Science Stipendium an, um die Ausbildung in den Bereichen Data Science und künstliche Intelligenz für ehrenamtliche Zwecke zu fördern. Das Stipendium umfasst eine vollständige Übernahme der Kursgebühren für das Data Science Bootcamp von IOMIDS.
DE
August 2023

Der zweite Datendialog in Kooperation mit der Bertelsmann Stiftung war ein voller Erfolg: 1,5 Tage #Data4Good mit vielen neuen Impulsen von 35 Teilnehmer*innen aus der CorrelAid Community für drei Forschungsgruppen der Bertelsmann Stiftung.
EN
August 2023

Our CorrelAid Mentoring Program has just concluded its third year, soon round number four will be kicked off. Keep reading to learn how we connect over 100 data enthusiasts in our CorrelAid network each year to enable them to learn from each other in mentoring pairs.
DE
August 2023

Mit dem zwölfteiligen Kurs “R Lernen von und für die Zivilgesellschaft – Der Datenkurs für Anfänger*innen” wollen wir von CorrelAid e.V. die Menschen und Organisationen, die die Welt mit ihrer Arbeit besser machen wollen, dabei unterstützen, dies effektiver und effizienter zu tun - und das zum siebten Mal!


