Mithilfe von KI Wirkungsmessung skalieren
- Status
- Abgeschlossen
- Projektzeitraum
- Oktober 2023 – Juli 2024
- Partner
Mit zunehmender Größe der Organisation kann die Durchführung und insbesondere die Auswertung von Teilnehmerbefragungen zu einer Herausforderung werden. Im Rahmen eines Data4Good-Projekts entwickelten fünf Freiwillige von CorrelAid einen automatisierten Bewertungsprozess und eine Webanwendung für In safe hands e.V., um deren Wirkung zu messen.
In safe hands e.V. bietet mit BUNTER BALL ein sportpädagogisches Präventionsprogramm für Kinder im Grundschulalter an. Ziel ist es, nicht nur die Motorik der Kinder zu stärken, sondern auch ihre emotionalen und sozialen Kompetenzen zu verbessern. Um diesen Effekt zu überprüfen und die Ergebnisse messbar zu machen, werden vor und nach jedem Schuljahr standardisierte Interviews mit den teilnehmenden Kindern durchgeführt. Die unterstützenden Freiwilligen halten die Antworten der Kinder möglichst im Originalwortlaut fest.
In diesem Projekt wurden die Teile der Interviews ausgewertet, die sich mit dem sozial kompetenten Verhalten und den Emotionsregulationsstrategien der Kinder befassen. Die im Originalwortlaut aufgezeichneten Antworten müssen zur weiteren Auswertung verschiedenen Kategorien aus dem Freitext zugeordnet werden. Bisher wurde dieser Prozess manuell von geschultem Personal durchgeführt. Mit steigender Teilnehmerzahl wurde dies jedoch immer zeitaufwändiger, was die Auswertung erschwerte. Ziel war es daher, diesen Prozess zu vereinfachen und zumindest teilweise zu automatisieren.
In jeder der beiden Kategorien (sozial kompetentes Verhalten und Emotionsregulation) gibt es 6 Fragen. Den Kindern wird eine Beispielsituation vorgelegt und sie werden gefragt, was sie einer Person in dieser Situation empfehlen würden:
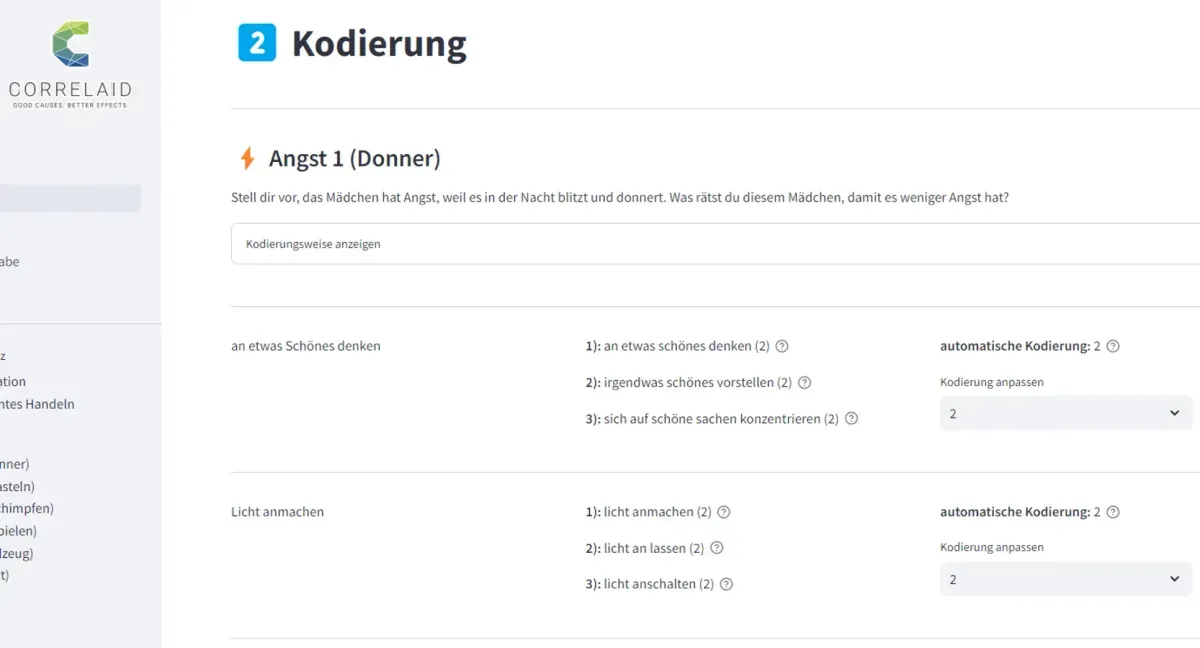
Stell dir vor, das Mädchen hat Angst, weil es in der Nacht blitzt und donnert. Was würdest du diesem Mädchen raten, damit es weniger Angst hat?
Beispiele für Antworten wären hier: „an etwas Schönes denken” oder „das Licht einschalten”. In diesen Antworten zeigt das Kind eine sogenannte adaptive Emotionsregulierungsstrategie – es weiß, wie es gut mit der Emotion umgehen kann – und erhält dafür zwei Punkte in der Bewertung. Verhaltensweisen, in denen das Kind sich selbst abwertet oder aggressiv reagiert, werden als maladaptive Emotionsregulierungsstrategien bezeichnet und mit 0 Punkten bewertet. Für andere Strategien wird ein Punkt vergeben.
Nach der Umsetzung des Projekts wird diese Zuordnung halbautomatisch durchgeführt. Das Tool soll Menschen im Bewertungsprozess nicht ersetzen, sondern sie unterstützen. Ziel ist es, Zeit bei einfachen Aufgaben zu sparen, damit mehr Zeit für die Bearbeitung schwieriger Fälle bleibt.
Das Tool unterstützt die Kodierung in zwei Schritten:
1. Auffinden ähnlicher Aussagen, die bereits kodiert wurden
Das System durchsucht eine Tabelle mit bereits kodierten Beispielen nach ähnlichen Aussagen und deren Kodierung, um sicherzustellen, dass gleiche oder ähnliche Aussagen immer die gleiche Punktzahl erhalten. Für diese Zuordnung werden sogenannte Wortvektoren oder Embeddings verwendet, sodass nicht unbedingt dieselben Wörter verwendet werden müssen, um eine Ähnlichkeit festzustellen: Für die Aussage „an etwas Schönes denken” findet das System beispielsweise den Satz „sich auf schöne Dinge konzentrieren” in den Trainingsdaten und für das Beispiel „das Licht einschalten” kann auch „das Licht anmachen” gefunden werden.
2. Automatische Kodierungsvorschläge
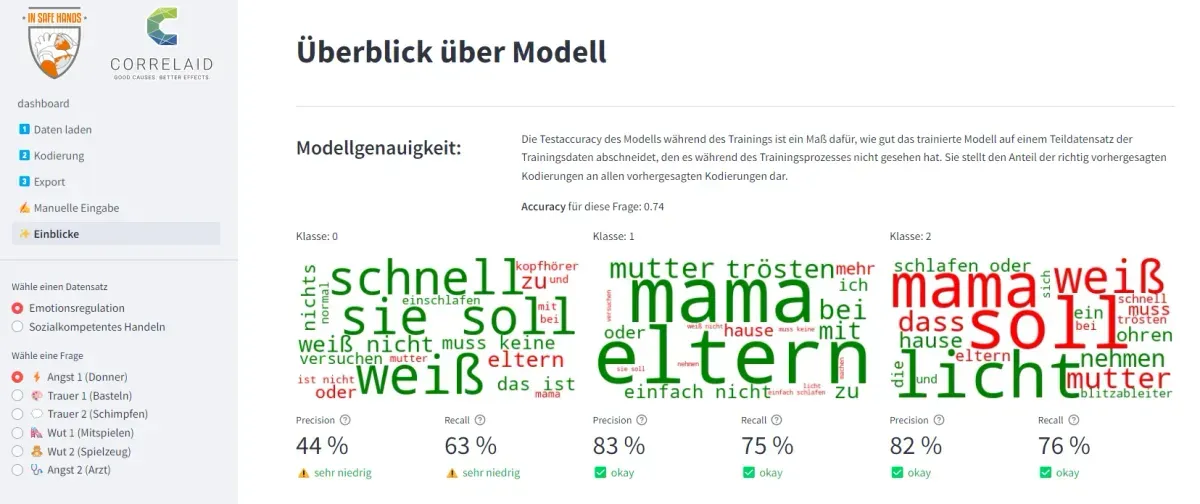
Es wird auch ein Kodierungsvorschlag berechnet. Hier kommt ein einfacher Bag-of-Words-Ansatz zum Einsatz. Dabei handelt es sich um einen maschinellen Lernansatz, bei dem die in einem Satz vorkommenden Wörter gezählt werden. Jedem Wort kann eine Gewichtung für eine bestimmte Kategorie zugewiesen werden. Das Wort „Licht“ oder „Ohren“ weist auf eine Kodierung mit zwei Punkten hin. Die Wortkombination „weiß nicht“ oder „nichts“ hingegen bedeutet 0 Punkte. Viele Aussagen, die auf die Beteiligung anderer Personen hinweisen und beispielsweise die Wörter „Mama“, „Mutter“ oder „Eltern“ enthalten, werden mit einem Punkt codiert. Dies ist ein sehr einfacher Ansatz, der sich insbesondere durch seine Erklärbarkeit auszeichnet. Es ist sehr leicht nachvollziehbar, warum das System eine bestimmte Codierung für eine Aussage vorschlägt.
Wenn diese beiden Ansätze voneinander abweichen und nicht zum gleichen Ergebnis führen, wird der entsprechende Eintrag mit einer Warnung versehen. Eine Meldung wird auch angezeigt, wenn das System sich bei der automatischen Kodierung nicht sicher ist, d. h. wenn der Konfidenzwert niedrig ist. Diese markierten Einträge können dann manuell überprüft und die Kodierung gegebenenfalls angepasst werden.
Wie geht es weiter?
Das System wird derzeit in einer ersten Phase für die Kodierung neuer Antworten eingesetzt. Das Tool wurde als Web-App für Mitarbeiter von In safe hands e.V. veröffentlicht und ist nur für eine autorisierte Personengruppe zugänglich. Natürlich gibt es bereits viele Ideen für die Weiterentwicklung und Verbesserung des Tools.
Einerseits können die Vorschläge durch kontinuierliches Training mit Daten aus neuen Umfragen ständig verbessert werden. Auch die Verbesserung der verwendeten Algorithmen für maschinelles Lernen und Sprachmodelle kann dazu beitragen. Uns war es wichtig, dass alle Berechnungen auf unserem eigenen Server stattfinden können und die Daten nicht an eine Schnittstelle von beispielsweise OpenAI oder Google gesendet werden müssen. Die großen Sprachmodelle (LLMs) werden sich jedoch sicherlich auch im nächsten Jahr noch deutlich weiterentwickeln und eine einfache Ausführung auf unseren eigenen Servern ohne großen Rechenaufwand ermöglichen.
CorrelAid Team
- Sören Etler (er/ihm)
- Philipp Wussow
- Jana Wilbert
- Alina Dallmann

