Does the glass floor show the truth?

During the 2025 German Data Science Days I already noticed the contrast between the venue's Art Nouveau setting (recall: naked Greek gods) and its techy agenda. This year I noticed a parallel to data science in the surroundings of the event: an inscription above the entrance to the auditorium reads, translated from German, "The true is godlike." It's likely a quote from Goethe's Wilhelm Meister's Journeyman Years, and (tbh I had to research this) in the book he continues: "[...] it appears not immediately; we must guess at it from its manifestations."
When I saw this at the event, I thought about the important role that ground truth plays in machine learning. Without getting too philosophical, the omitted part could be used to criticise machine learning: the data we use to train models only covers part of reality, and sometimes not accurately (think of biases). Ground truth is merely a manifestation of truth; ground truth is an imperfect representation of something that the model is then asked to generalise.
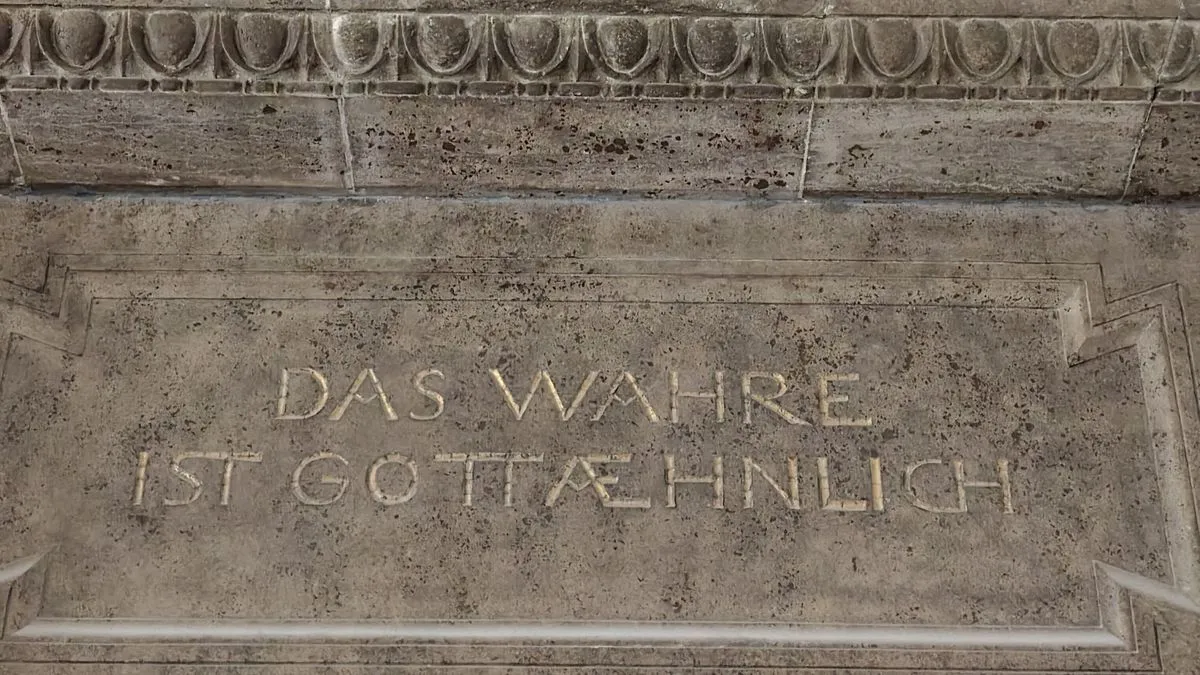
On the other hand, without getting too anti-capitalist, some of the talks could have been summed up by the motto: "Money is godlike, and we want it to appear immediately". However, I am grateful that this event was organised, because as last year, the invited speakers had diverse backgrounds, covered a wide range of topics and I learned a lot.
If AI is the new electricity, where is the surge protection?
The opening session on agentic AI was held by a lightning-protection and surge-protection company from Bavaria (Dehn). Therefore it was a low hanging fruit for the speaker to use the Andrew Ng quote "AI is the new electricity". I felt like there is additional joke potential that not only draws a parallel to electricity but also between AI Hype and surge protection.
Dehm developed an internal system that automates quote generation for the sales team: a custom retrieval-augmented stack with templated PDF creation driven by a knowledge graph. They claim around a 60% reduction in turnaround time. The speaker's framing was: We need Operating systems for agents versus isolated tools.
In the next talk on digital transformation, there was a slide with a presumably AI-generated image that caught my attention: a mechanically impossible rigid scale, with the potential of AI on one side and its risks on the other. While it's possible that I simply don't understand mechanics well enough, this is too ironic an example of hallucination risks and generative AI's lack of real-world understanding to leave out. The talk's better moments argued that productive AI value emerges from the interplay of data, domain knowledge, and generative models, not from any of the three alone.
What renewable energy and lightweight ML models have in common
The talk by FORRS opened with a finding that is both unfashionable and correct: lightweight ML with well-selected features can outperform complex architectures in predicting BESS (battery energy storage system) market dynamics. In the end, feature selection matters more than model choice. A striking fact I hadn't known: fossil energy providers sometimes offer power at negative prices, simply to undercut renewables on the market, much like complex neural models try to brute-force their way to results through raw compute and dataset size.
A researcher from Universität Hamburg picked up exactly where FORRS left off, in a talk called "The right model for the right time". If no single model works across all regimes in the energy pricing market, identify the regimes first, then route each to a specialist.
EnBW, an energy provider, gave the most politically interesting talk of the day. It was less about data science itself, and more about AI regulation, though it can be read as a broader argument about regulation in general. Their position, as I understood it: regulation is too complex, creates too much overhead, and would benefit from simplification. Good regulation has to account for the implementation level. Done well, it creates a level playing field, prevents a race to the bottom, and is itself a quality signal.
Where it got a little naive, in my view, is the claim that regulation is unnecessary in some cases because industry shares the same values as government and society and would therefore do the right thing without needing to document it. This is somewhat undermined by their earlier point about needing a level playing field precisely because of capitalistic pressures. If we all share the same values, why do we need laws at all?
Glass Floors and other important issues
A weird but somehow cool talk: ASB Glassfloor on the interactive glass sports floor. Glass floors have elastic properties that hardwood floors don't and the floor itself becomes a digital display that can display lines for different types of sports. I was reminded of Ubers "That's a bus"-moment, when I heard the latter, because that's something you can also do with cones, tape or chalk. But on top of that you can play dynamic training routines and you get sensors embedded in the floor that collect data for training analytics. Most importantly though, the floor becomes a new display for advertisements.
A researcher from the Charité brought the issue of rare diseases to our attention. With rare diseases comes a methodological problem: highly imbalanced class distributions and small sample sizes. This means that there is a high false positive rate for rare diseases and in consequence that symptoms are not a reliable cue for diagnosis. The Screen4Care initiative is lobbying for genetic newborn screening to shorten the path from symptom to diagnosis. Additionally they strive to improve data flow between hospitals through establishing a common data format, so data is sufficiently standardized for research and development of predictive algorithms.
GMDS (Deutsche Gesellschaft für Medizinische Informatik, Biometrie und Epidemiologie e.V.) and GI (Gesellschaft für Informatik e.V.) followed with a similar talk about how precision medicine requires a solid data basis. Their approach to increase available data is to promote the format of minimal standardized basic dataset. This dataset should be made available to allow translational research.
Steadforce held a talk with the interesting title: "From models to decisions: Data Science in sensitive medical contexts". The speaker shared the observation that data scientists often just optimize models, but that the impact of the model happens elsewhere. Another parallel to the Goethe quote in the beginning: it was said that ground truth is fuzzy and that models learn systems, not a disorder itself. I had to think about this well known example of a prediction algorithm that at first seemed to perform well in detecting tumors on images, but then it turned out to mostly have learned whether there was a ruler for measuring the tumor in the image.
The line that stuck with me: "Responsibility starts when predictions become decisions". A ML practitioner is not only responsible for improving metrics of model optimization, but monitoring also needs to cover output, performance, and governance. This requires observation of decisions, to evaluate impact, and to design for adaptation.
Metaverse on steroids
A researcher from TUM opened the final cluster of talks with a report on an impressive project: The Global Building Atlas, which has mapped 663 million building footprints worldwide. Earth Observation techniques made this possible, drawing on open satellite data from SENTINEL-2. The speaker noted that open satellite data often lacks the labeling needed to make it truly useful, and that their building atlas is laying a foundation for further research. For instance, one can now calculate how much energy we could produce by installing solar panels on every building in the world: 1.1 to 3.3 times the global energy demand. The speaker also raised a broader concern: while Earth observation reveals a great deal about the issues we face, these insights are too often not translated into policy.
The researcher also reported on the foundation models they are building. Foundation earth observation models allow the adaptation of a model to downstream tasks such as land-use classification or flood detection. A crazy model the speaker mentioned is DOFA-CLIP, which basically semantically indexes earth. This means that any patch of the planet, observed by radar, optical, multispectral, or hyperspectral sensors, can be embedded into a shared space alongside natural language. Instead of querying satellite archives by coordinates, dates, and sensor type, you can simply ask: "find solar farms under construction in Southern Europe," or "where is deforestation expanding into protected areas?"
A researcher from GFZ Helmholtz-Zentrum für Geoforschung started with the question whether we could have predicted the "Year without Summer" with today's means and what would be needed to create a digital twin of earth for running simulations of such events. Some of the technical challenges: missing data and harmonising data from many sources. Long story short, building a digital twin of earth is incredibly difficult, but people are working on it, for example within the Destination Earth Project.
And then another researcher from LMU closed the day with a talk titled: High Quality Data for Training and Alignment of AI Models. The alignment problem was framed as a survey research task that has well understood issues. Data annotation can show biases known from that area. For example, the longer a data worker labels hateful content, the more they get used to it and tend to underestimate severity. Also, data workers have a certain background not representative for society overall.
Alignment is also related to survey research in a different way. More and more often, LLM generations are used as data for survey research. How models are aligned obviously impacts the feasibility of that. The speaker mentioned a paper on voting outcome prediction: since LLMs are trained on huge amounts of text reflecting human attitudes, opinions, and political discourse, maybe they've absorbed enough about "what kind of person votes how" that they can stand in for real survey respondents. But no, GPT-3.5 could not accurately predict German voting behavior.
If last year's GDSD left me thinking civil society needs to watch how business actors translate AI hype into actual value, this year sharpened the thought. The most useful talks for a civil-society lens were the ones where someone had picked the right tool for a specific problem rather than the hyped one, and where tools were assessed in the context of their actual use. Open data continues to prove its worth, and data standardisation remains an important issue.
The program and some of the talk materials can be accessed here.